PEFT: LLM 参数高效微调
引言
SFT(Supervised Fine-Tuning,监督微调)对于我们并不陌生,在 BERT 时代模型微调就已经大行其道了。微调是深度学习中迁移学习的一种方法,其中预训练模型的权重会在新数据上进行训练。微调可以在整个神经网络上执行,也可以仅在其部分层上执行,此时未进行微调的层会被“冻结”(在反向传播步骤中不更新)。这种方式使得 SFT 适用于在特定领域或者特定任务上有针对性的提升模型效果
PEFT(Parameter-Efficient Fine-Tuning,参数高效微调)是一种针对大型预训练模型(LLM)进行下游任务适配时所使用的微调技术。与全参数微调(Full Fine-Tuning)不同,PEFT 在微调过程中仅更新模型的极少部分参数,同时保持预训练模型的主体参数冻结(即不计算梯度、不更新)。通过引入少量额外的、可训练的参数或结构,让模型高效地学习新任务
PEFT 方法分类

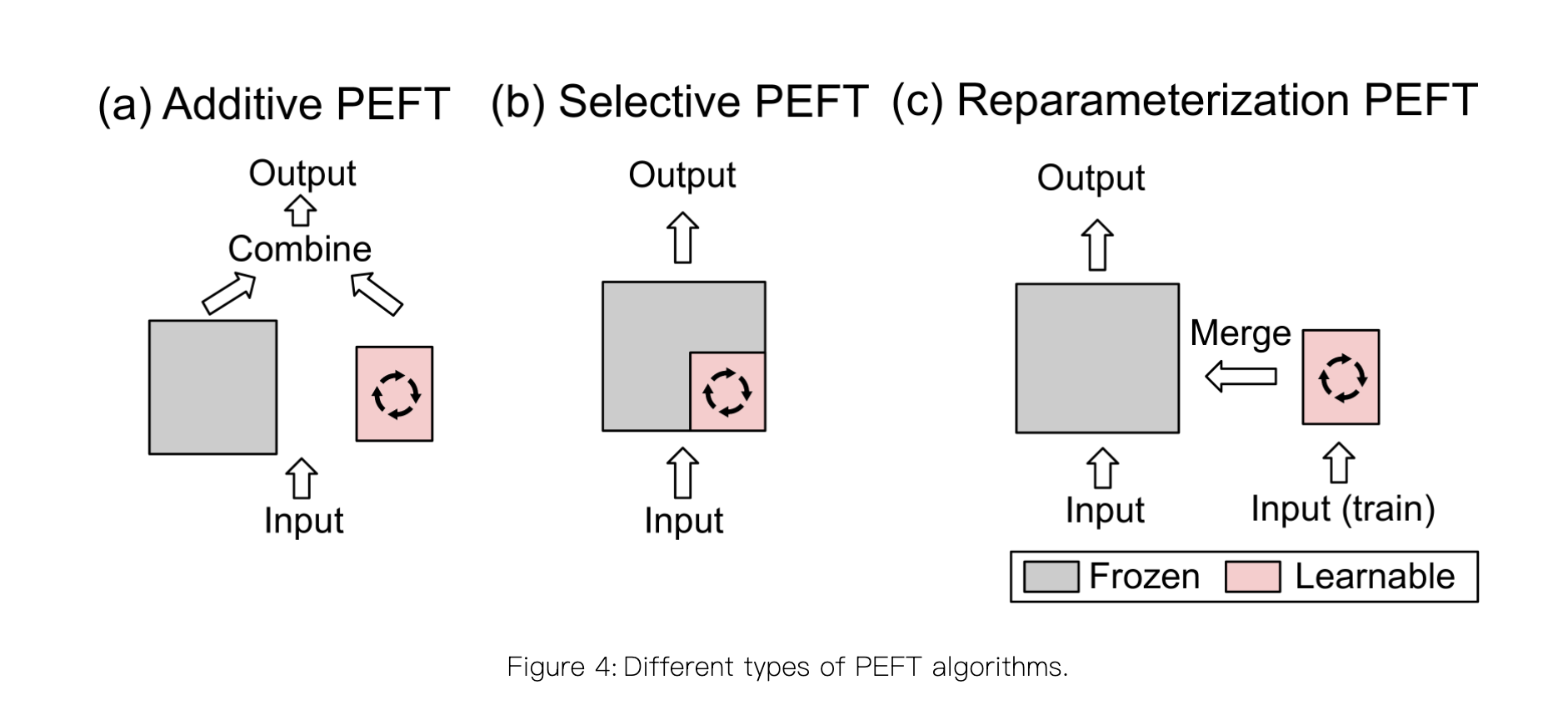
目前主流的参数高效微调(PEFT)策略大致可分为以下四类:
- reparameterized PEFT: 构建原始模型参数的(低维)重新参数化形式用于训练,然后在推理时将其等效转换回原始形式
- additive PEFT: 通过注入新的可训练模块或参数来修改模型架构
- selective PEFT: 在微调过程中使一部分参数子集变为可训练的
- hybrid PEFT: 结合不同参数高效微调方法的优点来构建一个统一的参数高效微调模型
Reparameterized PEFT
重参数化(Reparameterized)PEFT方法的核心思想是:通过数学变换,将预训练模型的参数转换为一种更高效的形式进行微调,而在推理时又可恢复为原始参数形式,从而在不引入额外推理延迟的前提下显著提升训练效率。这类方法尤其擅长为大型模型找出有效的低维表示
重参数化方法基于一个重要的理论支持,预训练大模型往往具有极低的内在维度(Intrinsic Dimensionality)。这意味着,尽管模型参数总量庞大,但针对特定任务进行微调时,所需的参数空间远小于模型的全参数空间。因此,我们可以通过寻找一组低维参数来高效地完成微调,其效果近似于在全参数空间中进行优化
wiki: 在线性代数中,一个矩阵的列秩是列向量生成的最大线性无关组的向量个数。类似地,行秩是矩阵的线性无关的横行的个数。矩阵的列秩和行秩总是相等的,因此它们可以简单地称作矩阵的秩(Rank)
重参数化方法通常会在训练阶段构建一个参数化的增量更新(如低秩分解),并将其应用于原始权重上。一旦训练完成,这个增量更新可以无缝地合并回原始权重中,使得微调后的模型在推理时与原始模型具有完全相同的结构和计算图,不会产生任何额外的计算开销
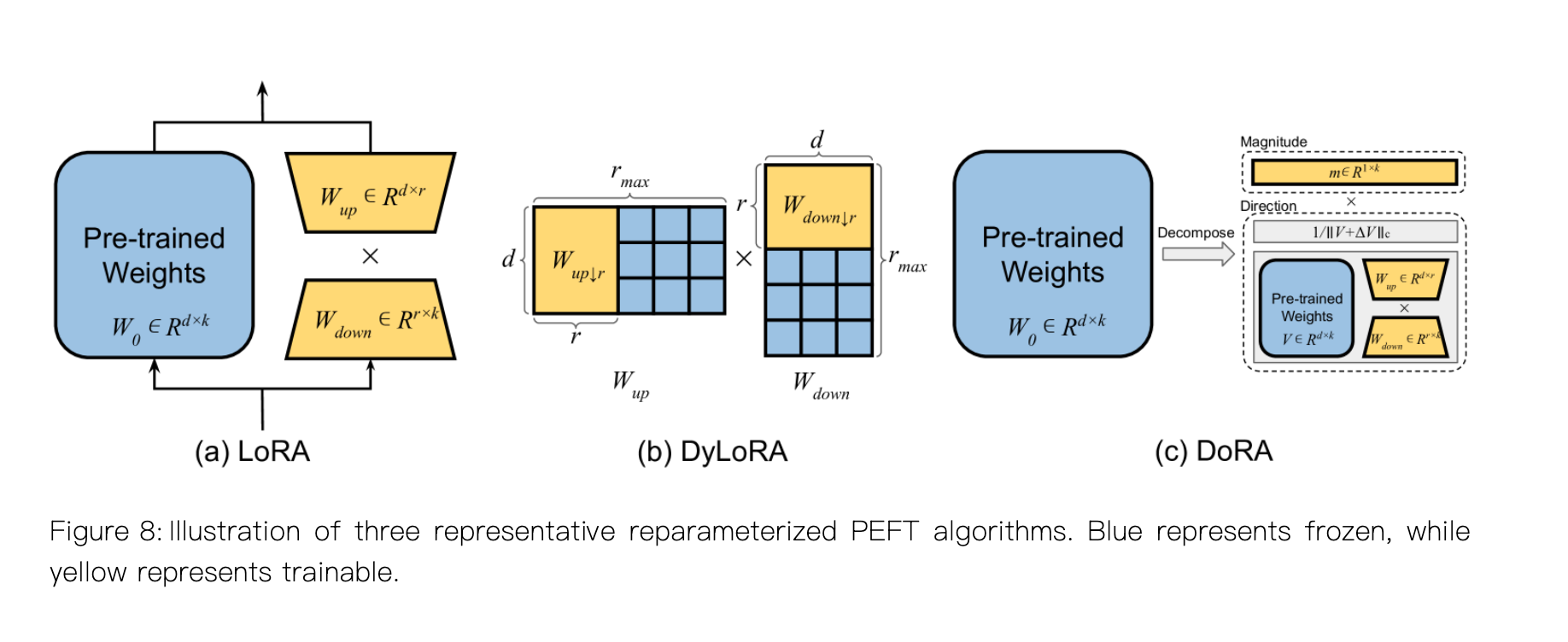
LoRA: 是当前最流行且最具影响力的重参数化PEFT方法,LoRA 假设模型权重在任务适配过程中的更新量具有低秩特性。对于一个预训练权重矩阵,LoRA 并不会对其直接进行更新,而是用两个低秩矩阵的乘积来近似这个更新量,它们与原始矩阵并行操作,最终缩放后合并到预训练权重矩阵中,整个过程如上图(a)中所示
上述公式中 $\alpha$ 表示缩放因子,在训练开始时,$W_{down}$ 使用随机高斯分布进行初始化,而$W_{up}$初始化为零,以确保$\Delta W$最初的值为零
LoRA 易于实现,在 Hugging Face PEFT 库中只需几行代码即可将 LoRA 适配器注入到开源的预训练模型中。一旦微调完成,LoRA 的自适应权重会无缝集成到预训练的骨干权重中。并且可训练参数数量极少,只占原始参数的0.01%级别
虽然 LoRA 使用简单且高效,但选择合适的秩一直是一个有挑战性的问题,这催生了大量的改进工作,如 DyLoRA、DoRA 等试图提供比简单固定的低秩加法更优的更新结构,如上图(b) (c)中所示的
Additive PEFT
适配器的思想首先在 CV 领域中被引入,以实现知识在多个视觉领域之间的高效迁移。顺序适配器将其扩展并应用于NLP任务,通过将适配器(可训练模块)插入Transformer块,并微调适配器的参数,使预训练语言模型(PLMs)高效的适应于下游任务
Adapter
具体来说,适配器网络依次插入 Transformer 的自注意力层和前馈层之后。每个适配器都是一个低秩模块,包含一个下投影、一个非线性激活函数、一个上投影以及一个残差连接。对于输入x,使用 ReLU 非线性激活函数的顺序适配器的输出可以由下述公式定义。在微调期间,只需更新适配器网络 $W_{up}$和 $W_{down}$的参数,即可使PLMs适应特定的下游任务。
顺序适配器的具体架构如下图所示: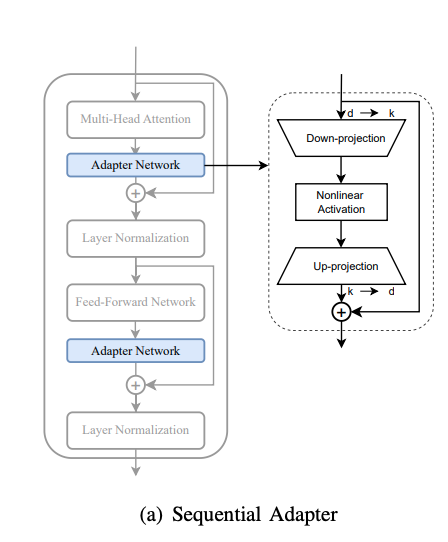
适配器在 NLP 领域的概念最初由序列适配器引入,其结构如下图(a)所示。该方法在每个 Transformer 块中增加了两个适配器模块,一个放置于自注意力层之后,另一个放置于FFN层之后。后续的研究旨在解决与适配器层相关的额外计算成本。将适配器层放置在 Transformer 模块内。这种方法可能会降低模型的并行性,需要在推理效率和准确性之间进行取舍。下图(b)中展示了一种并行适配器的方法,该方法将传统上顺序的适配器层重组为与每个Transformer子层并行运行的网络。类似的,CoDA 也采用了并行适配器设计。除了并行设计之外,CoDA采用了稀疏激活机制以提高推理效率,如图(c)所示。具体来说,CoDA使用一个软性 Top-k 选择过程,识别出每层中k个重要的词元,这些重要词元将同时被冻结的预训练 Transformer 层和适配器分支处理,以维持模型准确性。相比之下,那些不重要的词元则仅由适配器分支处理,而跳过了计算量大的预训练层,从而在不影响整体性能的前提下优化了推理效率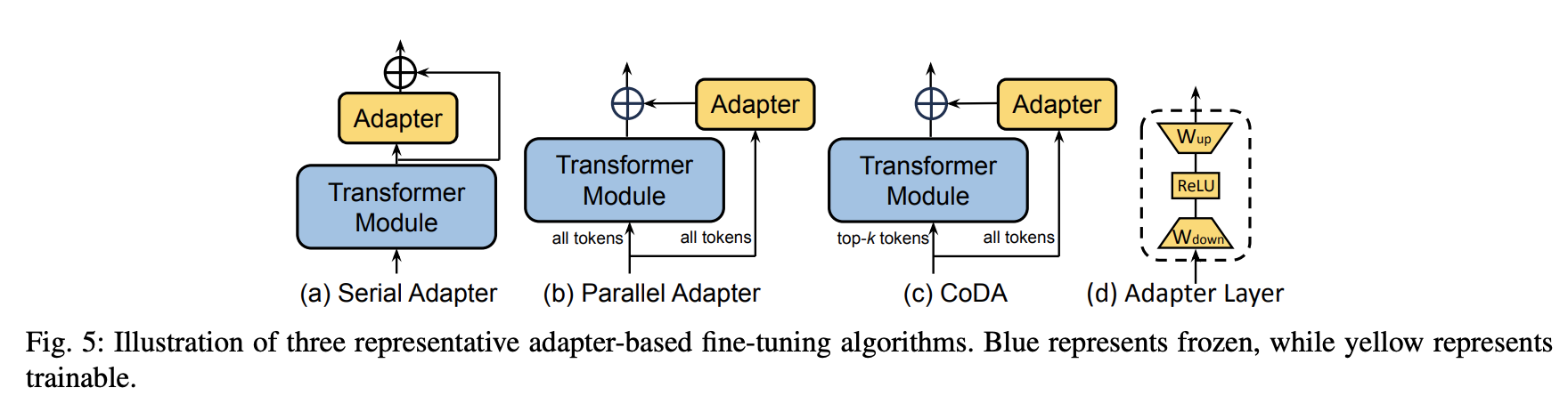
Soft Prompt
Prompt Tuning 是一种通过微调来改进模型性能的方法。与通过上下文学习优化离散的词元表示不同,soft prompts 通过添加连续嵌入向量到输入序列的开头,期望通过向量空间来学到更多的信息
Prefix Tuning
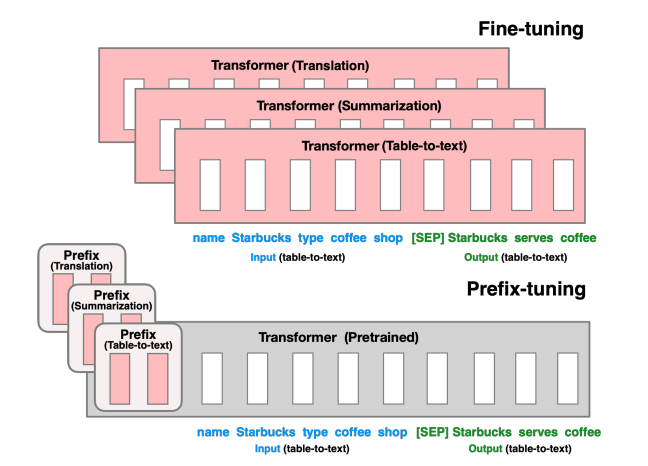
如上图,全量微调会更新语言模型(LM)的所有参数(红色的 Transformer 模块),并且针对每个任务都需要存储完整的模型副本。Prefix Tuning 提出了前缀调优方法,该方法冻结语言模型的参数,仅对前缀(红色的前缀块)进行优化。因此,针对每个任务只需存储前缀,这使得前缀调优具有模块化特性且节省空间
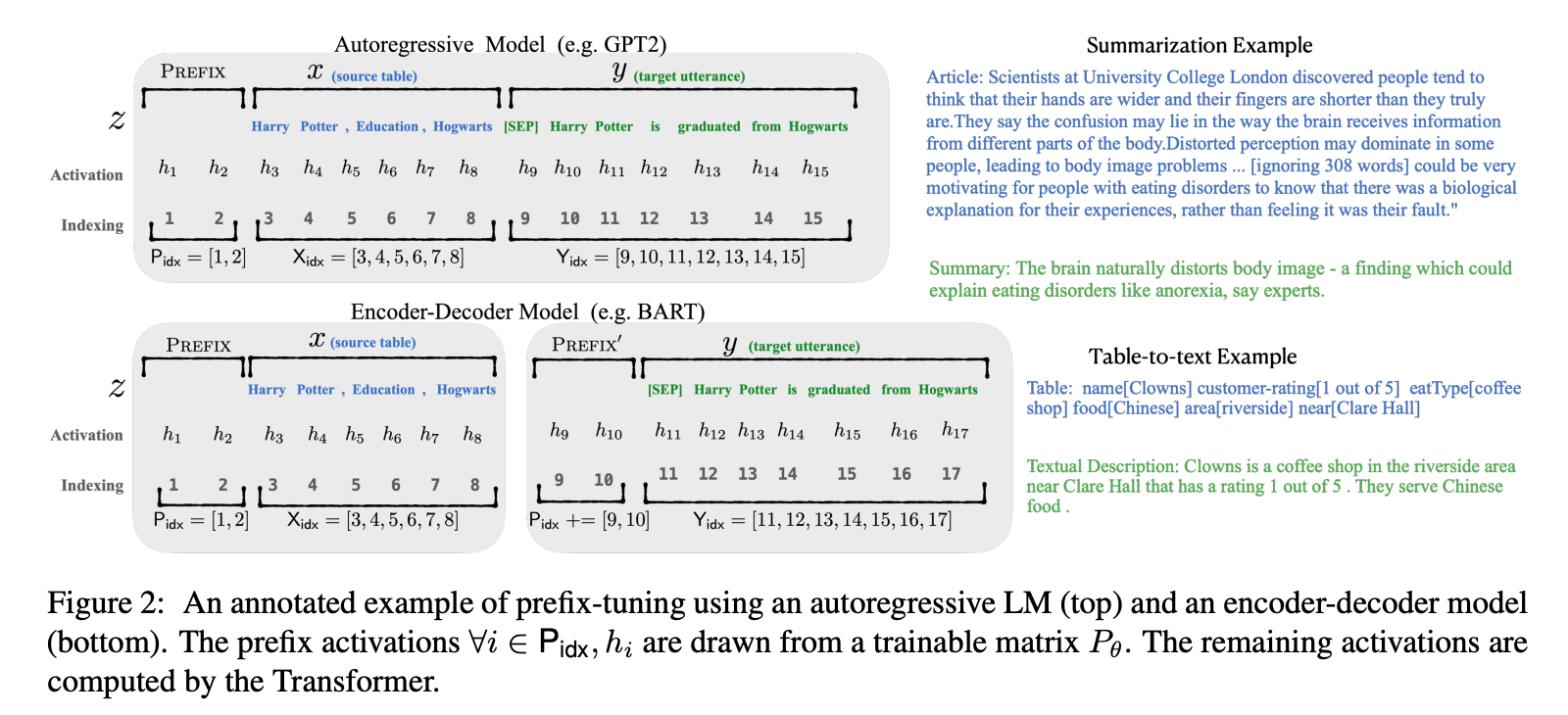
如上图,prefix tuning 为 decoder-only 模型 添加一个前缀,得到$z=[PREFIX; x; y]$; 或者为 encoder-decoder 模型都添加前缀,得到$z=[PREFIX; x; PREFIX^{‘}; y]$。$P_{idx}$表示前缀索引序列,前缀索引对应的激活值是自由参数,且前缀激活值始终处于左侧上下文,因此会影响右侧的任何激活值
P-Tuning
P-Tuning 将可训练的连续提示嵌入(continuous prompt embeddings)与离散提示(discrete prompt)相结合使用。具体而言,给定一个离散提示作为输入,P-Tuning 将连续提示嵌入与离散提示词元拼接起来,并将其作为输入送入语言模型。连续提示通过反向传播进行更新,以优化任务目标
ps: P-Tuning V1 只在输入的时候加入 embedding 进行调整,且其位置可以自由选择,而 Prefix Tuning 更新的是每一层中与虚拟 token 位置对应的所有参数,包括 embedding 层以及虚拟 token 位置对应的每一层的 activation
P-Tuning V2
P-Tuning V1 的效果并不是很好,其表现远不如微调,远甚~。 P-Tuning v2 采用深度提示调优(deep prompt tuning),作为一种适用于不同规模模型和自然语言理解任务的通用解决方案。P-Tuning V1 的连续提示仅被插入到输入嵌入序列中,由于序列长度的限制,可调节的参数数量有限。为应对这个问题,P-Tuning v2 采用了深度提示调优,不同层的提示作为前缀词元被添加,P-Tuning v2 拥有更多可调节的参数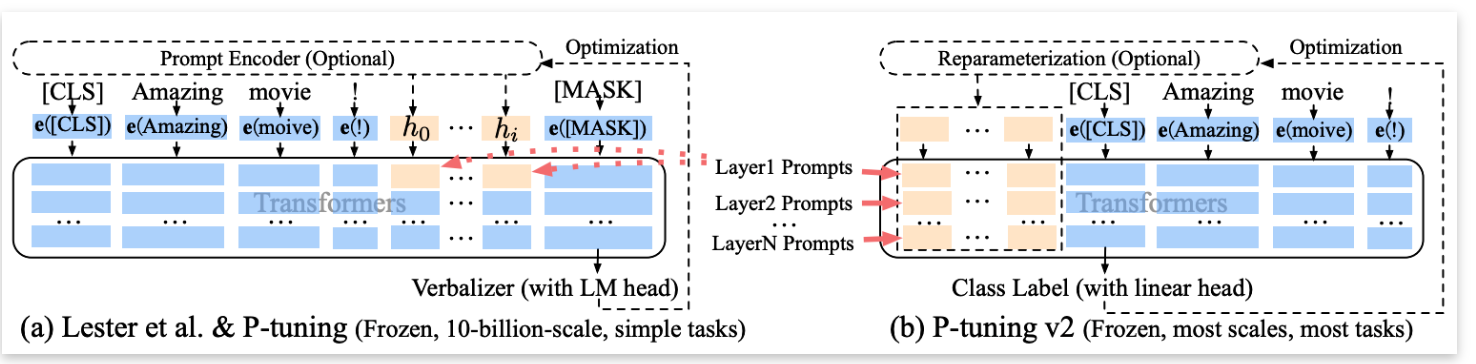
ps: 既然 P-Tuning V2 为每一层添加可学习的连续提示,那么它和 Prefix-Tuning 有什么区别呢?大的创新的思路上,我认为没什么区别。小的实现上,Prefix-Tuning 的注入位置仅在于 transformer 层的 KV 上,而 P-Tuning V2 是注入在 transformer 的每一层网络上
Selective PEFT
与通过增加额外参数来提高模型复杂度的 additive PEFT 不同,Selective PEFT 会选择现有参数的一个子集进行微调。对于一个参数为的模型:
其中每个$\theta_{i}$代表一个独立的参数,n表示这些参数的总数。Selective PEFT 的过程是通过对这些参数应用一个二进制掩码 $M=m_{1},m_{2}…,m_{n}$,其中每个$m_{i}$的取值为1或者0,代表与之对应的$\theta_{i}$是否被选中进行微调。如何选择部分参数进行微调,后续有很多工作基于此想法来进行优化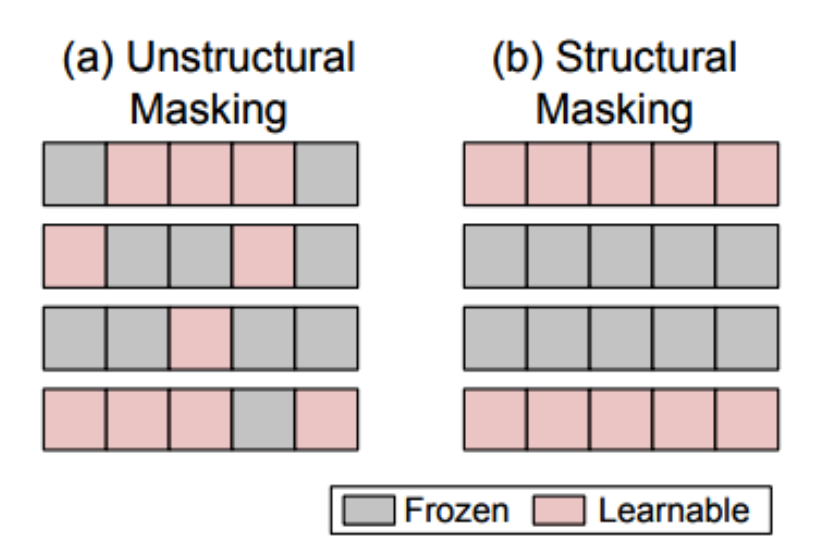
展望
虽然现在 LLM 的迭代越来越朝着 AGI 方向来发展,垂域微调常常比不上闭源商用大模型迭代所带来的收益。但是在有些数据敏感、对时效性有高要求、需要私有化部署的场景下,不同技术路线的微调技术还是有用武之地的
参考文献
- [1] Parameter-Efficient Fine-Tuning for Large Models:
A Comprehensive Survey - [2] Prefix-Tuning: Optimizing Continuous Prompts for Generation
- [3] LLM微调方法(Efficient-Tuning)六大主流方法
- [4] 矩阵的有效秩(Effective Rank)