本文整理自知乎专栏《深度强化学习》,对应王树森老师的深度强化学习课程。
视频课程:B站 BV12o4y197US
官方课件:GitHub wangshusen/DRL
一、基本概念(笔记1)
原文链接:知乎 p/651498960
1.1 概率论基础
随机变量
随机变量是一个值取决于随机事件结果的变量。大写字母 $X$ 表示随机变量,小写字母 $x$ 表示观测值(已确定,无随机性)。
概率密度函数(PDF)
概率密度函数 $p(x)$ 描述随机变量取某个特定值的相对可能性。以高斯分布为例:
期望
函数 $f(x)$ 关于随机变量 $X$ 的期望:
- 连续形式:$\mathbb{E}[f(X)] = \int p(x) \cdot f(x) dx$
- 离散形式:$\mathbb{E}[f(X)] = \sum p(x) \cdot f(x)$
1.2 强化学习核心术语
| 术语 | 含义 | |
|---|---|---|
| State $s$ | 某一时刻系统/环境的观测信息 | |
| Action $a$ | Agent 在某一状态下执行的操作 | |
| Agent | 动作的执行者(决策者) | |
| Environment | Agent 之外的一切 | |
| Policy $\pi(a\ | s)$ | 在状态 $s$ 下采取动作 $a$ 的概率 |
| Reward $R_t$ | 执行动作后环境给予的即时反馈 | |
| State Transition $p(s’\ | s,a)$ | 状态转移概率 |
策略函数
值域 $[0, 1]$,对所有动作求和等于 1:$\sum_a \pi(a|s) = 1$
状态转移
满足马尔可夫性质:下一状态只取决于当前状态和动作。
1.3 Agent 与环境的交互
- Agent 观测当前状态 $S_t$
- 根据策略 $\pi(a|s_t)$ 做随机抽样,选择动作 $a_t$
- 环境执行状态转移,生成新状态 $S_{t+1}$
- 环境返回奖励 $R_t$
- 重复直到终止
随机性的两个来源:
- 动作的随机性:$P(A=a|S=s) = \pi(a|s)$
- 状态转移的随机性:$P(S’=s’|S=s, A=a) = p(s’|s,a)$
轨迹(Trajectory):$(s_1, a_1, r_1, s_2, a_2, r_2, …, s_T, a_T, r_T)$
1.4 折扣回报(Discounted Return)
其中 $\gamma \in [0, 1)$ 是折扣因子。$\gamma$ 越接近 0 越”短视”,越接近 1 越”远视”。
1.5 价值函数
动作价值函数
表示在状态 $s_t$ 采取动作 $a_t$ 后,遵循策略 $\pi$ 的期望回报。
最优动作价值函数
状态价值函数
$V_\pi(s)$ 越大,策略 $\pi$ 在状态 $s$ 上表现越好。
1.6 两大学习方法
- Policy-Based:直接学习策略函数 $\pi(a|s;\theta)$
- Value-Based:学习 $Q^(s,a)$,选择 $a_t = \arg\max_a Q^(s_t, a)$
二、价值学习 Value-Based Learning(笔记2)
原文链接:知乎 p/651525759
2.1 核心思想
学习最优动作价值函数 $Q^*(s, a)$,用于决策:
2.2 DQN(Deep Q-Network)
用神经网络 $Q(s, a; w)$ 近似 $Q^*(s, a)$:
- 输入:状态 $s$(如游戏画面)
- 卷积层提取特征
- 全连接层输出所有动作的评分向量
- 选择分数最高的动作执行
2.3 TD Learning(时序差分学习)
不需要经历完整 episode 就能更新模型参数。
TD 目标:
TD 误差:
损失函数:
更新规则:
2.4 DQN 训练流程
- 观测状态 $s_t$,用 $\epsilon$-贪心策略选择动作 $a_t$
- 执行 $a_t$,获得奖励 $r_t$ 和新状态 $s_{t+1}$
- 计算 TD 目标:$y_t = r_t + \gamma \cdot \max_a Q(s_{t+1}, a; w)$
- 计算 TD 误差:$\delta_t = Q(s_t, a_t; w) - y_t$
- 梯度下降更新:$w \leftarrow w - \alpha \cdot \delta_t \cdot \nabla_w Q(s_t, a_t; w)$
2.5 $\epsilon$-贪心策略
平衡探索与利用:
- 以概率 $1-\epsilon$ 选择当前最优动作(利用)
- 以概率 $\epsilon$ 随机选择动作(探索)
三、策略学习 Policy-Based Learning(笔记3)
原文链接:知乎 p/651634475
3.1 策略网络
用神经网络 $\pi(a|s; \theta)$ 近似策略函数。对于离散动作空间,输出层使用 Softmax 保证输出是有效概率分布。
3.2 目标函数
通过梯度上升最大化 $J(\theta)$。
3.3 策略梯度定理
利用对数技巧(log-derivative trick):
得到策略梯度定理:
蒙特卡洛近似
从策略中抽样一个动作 $\hat{a}$:
3.4 REINFORCE 算法
用实际观测的折扣回报 $u_t$ 近似 $Q_\pi(s_t, a_t)$:
- 玩一整局游戏,收集轨迹 $(s_1, a_1, r_1, …, s_T, a_T, r_T)$
- 计算折扣回报:$u_t = \sum_{i=t}^{T} \gamma^{i-t} r_i$
- 更新参数:$\theta \leftarrow \theta + \beta \cdot u_t \cdot \nabla_\theta \ln \pi(a_t | s_t; \theta)$
特性:
- On-Policy:每次更新后旧数据不能再用
- 必须完成完整 Episode
- 高方差
- 不能使用经验回放
四、Actor-Critic 方法(笔记4)
原文链接:知乎 p/651762101
4.1 核心架构
| 网络 | 角色 | 功能 | |
|---|---|---|---|
| Actor(策略网络)$\pi(a\ | s; \theta)$ | “运动员” | 选择动作 |
| Critic(价值网络)$q(s, a; w)$ | “裁判” | 评估动作好坏 |
4.2 训练目标
- 更新 Actor:使状态价值 $V_\pi$ 增大(策略梯度上升)
- 更新 Critic:使评分更准确(最小化 TD 误差)
4.3 策略梯度
蒙特卡洛近似:
4.4 完整训练流程
- 观测状态 $s_t$
- 采样动作 $a_t \sim \pi(\cdot|s_t; \theta)$
- 执行 $a_t$,获得 $r_t$ 和 $s_{t+1}$
- 价值网络打分:$\hat{q}_t = q(s_t, a_t; w)$
- 采样 $a_{t+1}$,目标网络打分:$\hat{q}_{t+1}^- = q(s_{t+1}, a_{t+1}; w^-)$
- TD 目标:$y_t^- = r_t + \gamma \cdot \hat{q}_{t+1}^-$
- TD 误差:$\delta_t = \hat{q}_t - y_t^-$
- 更新 Critic:$w \leftarrow w - \alpha \cdot \delta_t \cdot \nabla_w q(s_t, a_t; w)$
- 更新 Actor:$\theta \leftarrow \theta + \beta \cdot \hat{q}_t \cdot \nabla_\theta \ln \pi(a_t|s_t; \theta)$
- 软更新目标网络:$w^- \leftarrow \tau w + (1-\tau) w^-$
五、蒙特卡洛算法(笔记5)
原文链接:知乎 p/651863429
5.1 核心思想
蒙特卡洛方法通过随机样本来估计真实值:“模拟 → 抽样 → 估值”。
5.2 经典应用
估计 $\pi$ 值
在 $[-1,+1] \times [-1,+1]$ 正方形内随机生成 $n$ 个点,统计落入单位圆的点数 $m$:
近似积分
近似期望(最重要)
其中 $x_i$ 根据 $p(x)$ 随机抽样。
5.3 在强化学习中的应用
REINFORCE 算法就是蒙特卡洛方法:用实际回报 $u_t$ 近似 $Q_\pi(s_t, a_t)$。
蒙特卡洛 vs 自举(TD):
| 特性 | 蒙特卡洛 | TD |
|---|---|---|
| 需要完整轨迹 | 是 | 否 |
| 偏差 | 无偏 | 有偏 |
| 方差 | 高 | 低 |
| 典型算法 | REINFORCE | SARSA, Q-Learning, A2C |
六、SARSA 算法(笔记6)
原文链接:知乎 p/652009338
6.1 核心定义
SARSA 是同策略(On-policy) TD 学习算法,每次更新需要五元组 $(S_t, A_t, R_t, S_{t+1}, A_{t+1})$。
目的:学习 $Q_\pi(s, a)$(当前策略的价值),而非 $Q^*$。
6.2 TD 目标
注意:$a_{t+1}$ 是实际按照策略 $\pi$ 执行的动作(不是 max)。
6.3 表格形式 SARSA
- 初始化 Q 表
- 观测 $s_t$,$\epsilon$-贪心选择 $a_t$
- 执行 $a_t$,获得 $r_t, s_{t+1}$
- $\epsilon$-贪心选择 $a_{t+1}$
- TD 目标:$y_t = r_t + \gamma \cdot Q(s_{t+1}, a_{t+1})$
- 更新:$Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha [y_t - Q(s_t, a_t)]$
6.4 SARSA vs Q-Learning
| 维度 | SARSA | Q-Learning |
|---|---|---|
| 学习目标 | $Q_\pi$ | $Q^*$ |
| TD 目标 | $r_t + \gamma \cdot Q(s_{t+1}, a_{t+1})$ | $r_t + \gamma \cdot \max_a Q(s_{t+1}, a)$ |
| 策略类型 | On-policy | Off-policy |
| 经验回放 | 不能 | 可以 |
| 过高估计 | 无 | 有 |
七、Q-Learning 算法(笔记7)
原文链接:知乎 p/652218833
7.1 与 SARSA 的对比
| 算法 | 目标 | TD Target |
|---|---|---|
| SARSA | 学习 $Q_\pi$ | $r_t + \gamma \cdot Q(s_{t+1}, a_{t+1})$ |
| Q-Learning | 学习 $Q^*$ | $r_t + \gamma \cdot \max_a Q(s_{t+1}, a)$ |
7.2 TD Target 推导
当策略为最优策略 $\pi^$ 时,$A_{t+1}$ 选择使 $Q^$ 最大化的动作:
用蒙特卡洛近似:用观测到的 $r_t$ 近似 $R_t$,用 $s_{t+1}$ 近似 $S_{t+1}$。

7.3 表格形式
- 观测 $(s_t, a_t, r_t, s_{t+1})$
- 计算 TD Target:$y_t = r_t + \gamma \cdot \max_a Q^*(s_{t+1}, a)$
- 计算 TD Error:$\delta_t = Q^*(s_t, a_t) - y_t$
- 更新 Q 表:$Q^(s_t, a_t) \leftarrow Q^(s_t, a_t) - \alpha \cdot \delta_t$
7.4 DQN 形式
用 DQN $Q(s, a; w)$ 近似 $Q^*(s, a)$,将表格中的 Q 换成神经网络,用梯度下降更新参数 $w$。
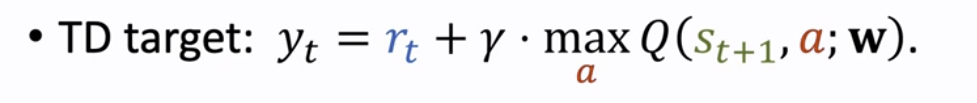
八、Multi-Step TD Target(笔记8)
原文链接:知乎 p/652320186
8.1 从单步到多步
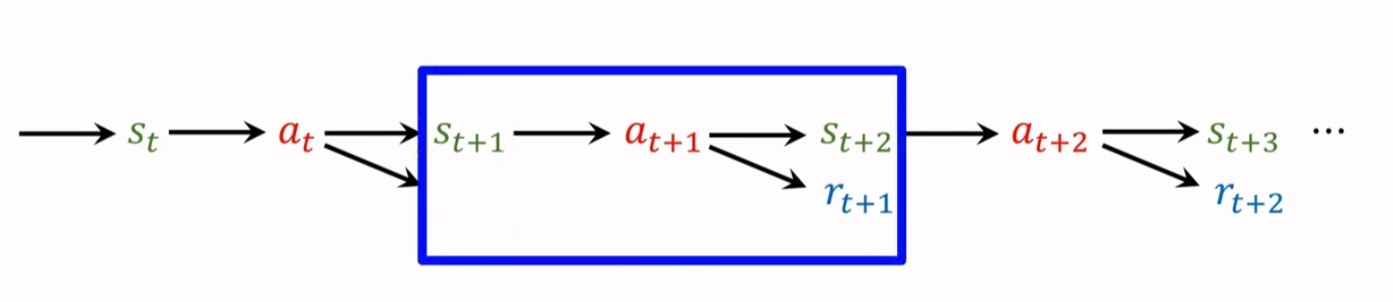
标准 TD 只使用一个奖励 $r_t$(One-Step),多步 TD 使用多个奖励。
8.2 多步回报
递归展开 $U_t$ 得到:
8.3 多步 TD Target
SARSA 的 m 步 TD Target:
Q-Learning 的 m 步 TD Target:
$m=1$ 为单步 TD(经典算法)的特例。
8.4 优势
多步 TD Target 更接近真实数据,偏差更小、结果更稳定。
九、经验回放 Experience Replay(笔记9)
原文链接:知乎 p/652330509
9.1 传统 TD 的问题
- 浪费经验:每个 transition 用完即丢
- 关联性更新:按时间顺序使用数据,前后关联性强,不利于训练
9.2 Replay Buffer
容量为 $n$ 的队列,存储 $n$ 条 transitions $(s_t, a_t, r_t, s_{t+1})$,满了则新替旧。
TD with Experience Replay:
- 从 buffer 中随机抽取 transition
- 计算 TD error 和梯度
- 用 SGD 更新参数
优势:打破经验相关性、重复利用过去经验。
9.3 优先经验回放(PER)
不同 transition 重要性不同,用 $|\delta_t|$(TD 误差绝对值)判断重要性。
核心思想:用非均匀抽样代替均匀抽样。
- 概率 $p_t$ 正比于 $|\delta_t| + \epsilon$
- $|\delta_t|$ 越大,被抽到的概率越高
- 概率大的 transition 学习率调小(补偿非均匀抽样的偏差)

十、高估问题、目标网络、DDQN(笔记10)
原文链接:知乎 p/652369341
10.1 TD 算法导致高估
两个原因:最大化(maximization) 和 自举(bootstrapping)。
自举导致的偏差传播
用一个估算去更新同类型的估算。若 $Q$ 函数高估下一状态的价值,误差会通过自举不断传播。
最大化导致的高估
对带噪声的 Q 值求最大化会导致系统性高估。
不均匀高估的危害
均匀高估无害(最优动作不变),但不同动作被高估程度不同时,会导致选择次优动作。
10.2 Target Network(目标网络)
解决自举问题。引入独立的目标网络 $Q(s,a; w^-)$:
- TD 目标:$y_t = r_t + \gamma \cdot \max_a Q(s_{t+1}, a; w^-)$
- 软更新:$w^- \leftarrow \tau \cdot w + (1-\tau) \cdot w^-$
10.3 Double DQN(DDQN)
解决最大化问题。将最大化拆分为两步:
- 用 DQN 选择动作:$a^* = \arg\max_a Q(s_{t+1}, a; w)$
- 用目标网络评估:$Q(s_{t+1}, a^*; w^-)$
TD 目标:
选择和评估使用不同网络,有效缓解高估。
| 问题 | 解决方案 |
|---|---|
| 自举导致的高估 | Target Network |
| 最大化导致的高估 | Double DQN |
十一、Dueling Network(笔记11)
原文链接:知乎 p/652812209
11.1 最优优势函数
$V^*$ 作为基准线,优势函数表示动作 $a$ 相对于基准的优势。
关键性质:$\max_a A^*(s,a) = 0$(最优动作的优势恰好为零)。
11.2 网络架构
- V 网络:输出标量(状态价值),参数 $w^V$
- A 网络:输出向量(每个动作的优势值),参数 $w^A$
- 两个网络共享卷积层
11.3 实践改进
用 mean 代替 max 效果更好:
11.4 训练方法
与 DQN 使用完全相同的算法。所有 DQN 改进技巧也适用:经验回放、DDQN、Multi-Step TD Target。
十二、策略梯度中的基准 Baseline(笔记12)
原文链接:知乎 p/652835396
12.1 Baseline 的引入
引入基准函数 $b(s)$(与动作 $a$ 无关),不改变梯度期望值:
因此策略梯度可以减去任意基准而不引入偏差:
12.2 为什么需要 Baseline?
如果所有 $Q$ 值都为正,所有动作概率都会被提高。引入 baseline 后:
- 好的动作($Q > b$)概率提高
- 差的动作($Q < b$)概率降低
信号更加清晰,方差显著减小。
12.3 选择 Baseline
此时 $Q_\pi(s,a) - V_\pi(s) = A_\pi(s,a)$ 即优势函数(Advantage Function)。
十三、REINFORCE with Baseline(笔记13)
原文链接:知乎 p/652860682
13.1 两个网络
- 策略网络 $\pi(a|s;\theta)$
- 价值网络 $v(s;w)$(用作 baseline)
13.2 算法流程
- 用策略网络玩一整局游戏,得到轨迹
- 从后往前计算折扣回报:$u_t = \sum_{k=t}^{T} \gamma^{k-t} r_k$
- 对每个时间步 $t$:
- 计算 TD 误差:$\delta_t = v(s_t; w) - u_t$
- 更新价值网络:$w \leftarrow w - \alpha \cdot \delta_t \cdot \nabla_w v(s_t;w)$
- 计算策略梯度:$g_t = (u_t - v(s_t;w)) \cdot \nabla_\theta \ln \pi(a_t|s_t;\theta)$
- 更新策略网络:$\theta \leftarrow \theta + \beta \cdot g_t$
13.3 关键说明
虽然同时学习策略网络和价值网络,但不属于 Actor-Critic,因为没有使用自举(bootstrapping),而是使用实际观测回报 $u_t$。价值网络仅做 baseline 降低方差。
十四、Advantage Actor-Critic A2C(笔记14)
原文链接:知乎 p/652898039
14.1 优势函数
衡量动作 $a$ 比”平均水平”好多少。
14.2 TD Error 近似优势函数
$\delta_t$ 是优势函数 $A_\pi(s_t, a_t)$ 的无偏估计。
14.3 A2C 训练流程(单步更新)
对每个 transition $(s_t, a_t, r_t, s_{t+1})$:
- TD target:$y_t = r_t + \gamma \cdot v(s_{t+1}; w)$
- TD error:$\delta_t = v(s_t; w) - y_t$
- 更新 Actor:$\theta \leftarrow \theta - \beta \cdot \delta_t \cdot \nabla_\theta \ln \pi(a_t|s_t;\theta)$
- 更新 Critic:$w \leftarrow w - \alpha \cdot \delta_t \cdot \nabla_w v(s_t; w)$
十五、REINFORCE 与 A2C 的异同(笔记15)
原文链接:知乎 p/652962638
15.1 相同点
- 都属于策略梯度方法
- 都使用策略网络和价值网络
- 都用价值网络作为 baseline 降低方差
15.2 核心区别
| 维度 | REINFORCE with Baseline | A2C |
|---|---|---|
| 回报估计 | 实际回报 $u_t$(蒙特卡洛) | TD target $r_t + \gamma v(s’; w)$ |
| 偏差-方差 | 无偏高方差 | 有偏低方差 |
| 更新频率 | 需要完整 episode | 每步都可更新 |
| 是否自举 | 否 | 是 |
| 是否 Actor-Critic | 不是 | 是 |
| 适用场景 | episodic 任务 | episodic + continuing |
15.3 统一视角
- 填 $u_t$ → REINFORCE with Baseline
- 填 $r_t + \gamma v(s_{t+1}; w)$ → A2C
- 填 $Q_w(s_t, a_t)$ → 标准 Actor-Critic
15.4 特例关系
当 A2C 使用 n-step return 且 $n \to \infty$(即整个 episode)时,退化为 REINFORCE。
十六、确定性策略梯度 DPG / DDPG(笔记17)
16.1 连续动作空间
以机械臂为例,动作空间 $\mathcal{A} \subset \mathbb{R}^d$。离散化会导致维度灾难(网格点数随自由度指数增长),需要直接处理连续空间。
16.2 确定性 Actor-Critic
| 网络 | 形式 | 功能 |
|---|---|---|
| Actor | $a = \mu(s; \theta)$ | 输入状态,直接输出确定性动作 |
| Critic | $q(s, a; w)$ | 评估动作好坏 |
注意:确定性策略 $\mu(s;\theta)$ 直接输出动作,不是概率分布。
16.3 用 TD 更新 Critic
给定 transition $(s_t, a_t, r_t, s_{t+1})$:
- $q_t = q(s_t, a_t; w)$
- $q_{t+1} = q(s_{t+1}, \mu(s_{t+1}; \theta); w)$
- TD error:$\delta_t = q_t - (r_t + \gamma \cdot q_{t+1})$
- 更新:$w \leftarrow w - \alpha \cdot \delta_t \cdot \nabla_w q(s_t, a_t; w)$
16.4 DPG 更新 Actor
通过链式法则:
梯度从价值网络输出反向传播,经过价值网络到动作 $a$,再经过策略网络到参数 $\theta$。
16.5 使用目标网络
引入目标网络 $q(s,a; w^-)$ 和 $\mu(s; \theta^-)$:
- $q_{t+1} = q(s_{t+1}, \mu(s_{t+1}; \theta^-); w^-)$
- 软更新:$w^- \leftarrow \tau w + (1-\tau)w^-$,$\theta^- \leftarrow \tau\theta + (1-\tau)\theta^-$
16.6 TD3 改进
TD3 (Twin Delayed DDPG) 针对 DDPG 高估问题的三大技巧:
- 截断双Q学习:两个 Critic,TD 目标取最小值
- 目标策略平滑:往目标动作中加截断正态噪声
- 延迟更新:每 $k$ 轮才更新一次 Actor 和目标网络
16.7 随机策略 vs 确定性策略
| 维度 | 随机策略 | 确定性策略 | |
|---|---|---|---|
| 形式 | $\pi(a\ | s;\theta)$ | $\mu(s;\theta)$ |
| 输出 | 概率分布 | 具体动作 | |
| 控制方式 | 从分布采样 | 直接使用 | |
| 应用场景 | 主要离散控制 | 连续控制 |
十七、置信域策略优化 TRPO(笔记19)
17.1 置信域概念
设 $\mathcal{N}(\theta_{old})$ 是 $\theta_{old}$ 的邻域:
如果函数 $L(\theta | \theta_{old})$ 能在此邻域中很好地近似 $J(\theta)$,则称其为置信域。
17.2 置信域算法
反复执行两步:
- 近似:构造 $L(\theta | \theta_{old})$ 近似 $J(\theta)$
- 最大化:$\theta_{new} \leftarrow \arg\max_{\theta \in \mathcal{N}(\theta_{old})} L(\theta | \theta_{old})$
17.3 TRPO 的目标函数
引入重要性采样:
其中 $\frac{\pi(A|S;\theta)}{\pi(A|S;\theta_{old})}$ 为重要性采样比率。
17.4 近似步骤
- 用 $\pi(\cdot|s; \theta_{old})$ 收集轨迹 $(s_1,a_1,r_1,…,s_n,a_n,r_n)$
- 计算折扣回报 $u_i$ 近似 $Q_\pi(s_i, a_i)$
- 构造近似函数:
17.5 最大化步骤
置信域约束的两种方式:
| 方式 | 公式 | 特点 | |||
|---|---|---|---|---|---|
| 参数空间约束 | $\ | \theta - \theta_{old}\ | < \Delta$ | 直接限制参数变化 | |
| KL 散度约束 | $\frac{1}{n}\sum_i \text{KL}[\pi(\cdot\ | s_i;\theta_{old}) \ | \pi(\cdot\ | s_i;\theta)] < \Delta$ | TRPO 推荐,直接度量策略变化 |
17.6 策略梯度 vs TRPO
两者都最大化 $J(\theta) = \mathbb{E}_S[V_\pi(S)]$,区别在于优化方法:
- 策略梯度:随机梯度上升
- TRPO:置信域算法,限制每步更新幅度,避免步长选择不当导致的训练不稳定
17.7 与 PPO 的关系
PPO 是 TRPO 的简化版本:
| 维度 | TRPO | PPO |
|---|---|---|
| 约束方式 | KL 散度硬约束 | 截断概率比率 $[1-\epsilon, 1+\epsilon]$ |
| 求解方法 | 共轭梯度法 | 简单梯度下降 |
| 计算复杂度 | $O(n^3)$ | $O(n)$ |
| 实现难度 | 复杂 | 简单 |
附录:全系列文章索引
| 编号 | 标题 | 链接 |
|---|---|---|
| 1 | 基本概念 | p/651498960 |
| 2 | 价值学习 Value-Based Learning | p/651525759 |
| 3 | 策略学习 Policy-Based Learning | p/651634475 |
| 4 | Actor-Critic Method | p/651762101 |
| 5 | 蒙特卡洛算法 Monte Carlo | p/651863429 |
| 6 | SARSA 算法 | p/652009338 |
| 7 | Q-Learning 算法 | p/652218833 |
| 8 | Multi-Step TD Target | p/652320186 |
| 9 | 经验回放 Experience Replay | p/652330509 |
| 10 | 高估问题、目标网络、DDQN | p/652369341 |
| 11 | Dueling Network | p/652812209 |
| 12 | 策略梯度中的基准 Baseline | p/652835396 |
| 13 | REINFORCE with Baseline | p/652860682 |
| 14 | Advantage Actor-Critic (A2C) | p/652898039 |
| 15 | REINFORCE 与 A2C 的异同 | p/652962638 |
| 17 | 确定性策略梯度 DPG | p/653041760 |
| 19 | 置信域策略优化 TRPO | p/653094745 |
注:笔记 16、18、20 在专栏中未找到,可能作者尚未发布。
参考资料:王树森 DRL GitHub | B站课程